
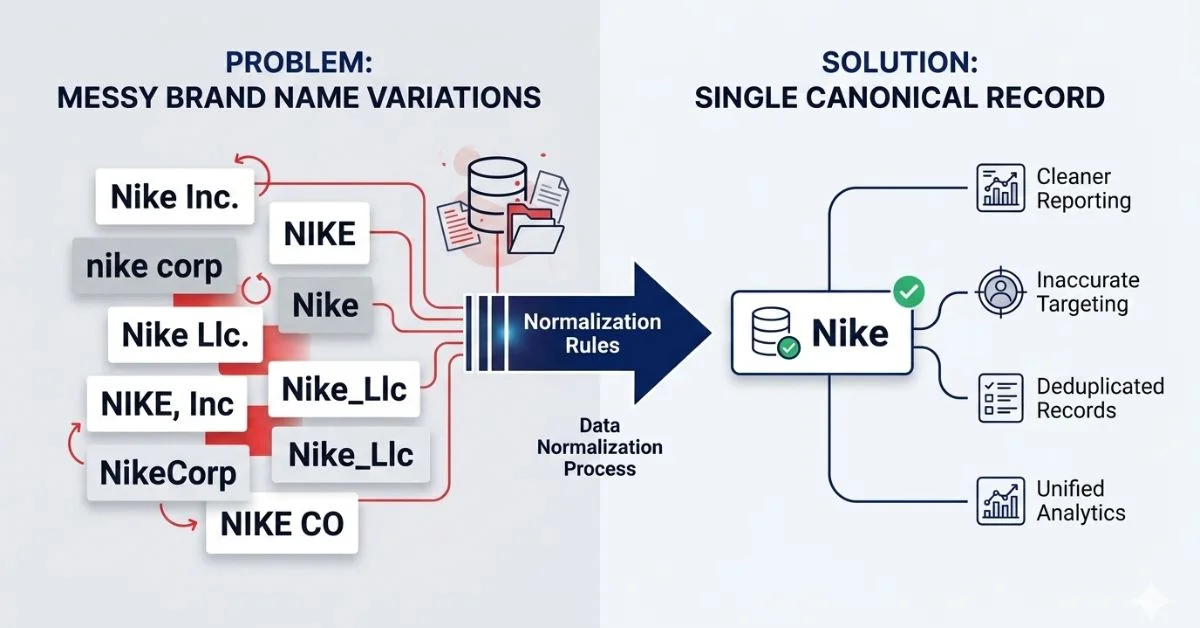

Somewhere in your CRM right now, there’s a company listed three different ways. “Nike,” “Nike Inc.,” and “NIKE” — all pointing to the same brand, all treated as separate entities by your analytics platform. This is exactly the problem that brand name normalization rules are designed to solve. They’re not glamorous. Nobody puts them on a slide deck.
But the businesses that get them right see faster sales cycles, cleaner reporting, and ad campaigns that actually reach the right people. The ones that ignore them? They spend 20–30% of their marketing budget chasing ghosts in duplicate records.
Here’s the full breakdown of what these rules are, why they matter, and exactly how to apply them in 2026.
What Brand Name Normalization Rules Actually Mean
Strip away the technical framing and the concept is simple. Brand name normalization rules are a set of techniques designed to standardize brand names so they appear consistently everywhere — in databases, on websites, and across marketing platforms.
Normalization rules act as a corrective framework. They transform inconsistent brand inputs into a single, authoritative representation known as the canonical brand name — allowing businesses to treat all references to a brand as one unified entity, regardless of how the name originally appeared in raw data.
Think of it as giving every brand name a permanent home address. No matter how someone types it — abbreviated, lowercased, with a comma, without one — the system always routes it to the same canonical record.
And the stakes are real. Bad CRM data costs B2B companies an estimated 20–30% of their sales and marketing budget through duplicate outreach, inaccurate segmentation, and broken attribution. That’s not a rounding error. That’s a budget line item silently bleeding out.
The Core Rules — Applied in Order
This is where most guides go wrong. They list rules without telling you the sequence matters. Each transformation depends on the clean state created by the one before it. Skip ahead and you’ll introduce new inconsistencies while fixing old ones.
Rule 1: Strip Legal Suffixes First
Legal suffixes like Inc., LLC, Corp., Ltd., GmbH, and S.A. serve corporate compliance purposes but add massive noise to operational data. For data deduplication, they provide zero signal—’Salesforce Inc.’ and ‘Salesforce Corp’ point to the identical entity. Your first rule must systematically strip these suffixes and expand standardized corporate abbreviations (e.g., converting ‘P&G’ to ‘Procter & Gamble’). The only caveat is maintaining a strict exception list for brands where the legal term is baked into their public identity.
Rule 2: Standardize Capitalization
Capitalization discrepancies are the most common cause of duplicate CRM records, as unconfigured systems treat lowercase and uppercase inputs as entirely separate entities. To fix this, enforce Title Case as your default global standard. You should establish two automated exceptions to this rule: keep short acronyms under four letters completely uppercase (e.g., ‘IBM’), and preserve verified, intentionally lower-cased or camel-cased brand styles (e.g., ‘adidas’, ‘eBay’, ‘iPhone’).
Rule 3: Remove Punctuation and Special Characters
Commas after company names, registered trademark symbols, periods in abbreviations — all of it creates variation your system treats as unique. Strip it during ingestion, not after records already exist downstream.
From an SEO perspective, inconsistent brand naming weakens topical authority and brand recognition in search engines. In customer data systems, it leads to duplicate records and incomplete customer profiles.
Rule 4: Fix Whitespace
Double spaces, trailing spaces, tabs that came in through CSV imports — these are invisible killers. A brand name with a trailing space won’t match the same name without one. Run whitespace normalization before any matching logic runs.
Rule 5: Separate Operational Names From Legal Names
Your operational name for a partner — what appears in your CRM, dashboards, and communications — and their legal business name — what appears on contracts and compliance documents — serve different purposes. Conflating the two creates problems in both directions: overly formal names in marketing contexts, and casual nicknames in legal documents. Maintain separate fields. Normalize each independently.
This is a detail most small teams skip. It costs them later when legal and marketing are pulling different records and neither knows it.
Also Read: Intelligent Frame Creation: The Hidden TV Feature That Changes Everything
What the Research Shows
Unstandardized brand records and messy customer data represent a silent tax on enterprise growth. Shifting to automated data normalization rules shows concrete operational improvements across the industry:
| Data Quality Metric | Before Normalization | After Enforcing Rules |
| CRM Duplicate Record Rate | 30% average duplicates | Dropped to 9% (PayFit Case Study) |
| Inbound Lead Matching Accuracy | Baseline system failures | 30% – 50% improvement scale |
| Product Information (PIM) Accuracy | Inconsistent attributes | 99.9% precision rate |
| Overall Revenue Leakage / Waste | 12% – 15% budget inefficiency | 1% – 2% direct lift in marketing ROI |
The cost of doing nothing is no longer theoretical. Cleaning database errors after the fact is complex, resource-intensive, and rarely fully effective. True data integrity requires normalization rules to sit directly at the point of data ingestion.
Where Inconsistency Comes From
Understanding the source stops the problem at the door.
Brand name variations creep in from several places simultaneously. Web forms let users type whatever they want. CSV imports from third-party vendors arrive with their own naming conventions. Manual data entry by sales reps under pressure produces shortcuts and typos. Enrichment tools pull from different canonical sources that don’t agree with each other.
Data that enters your systems from web forms, CSV imports, third-party enrichment tools, and manual entry will immediately diverge. No analytics platform, AI tool, or sales workflow can compensate for that divergence downstream.
Which is exactly why normalization needs to happen at ingestion — not as a quarterly cleanup. Cleaning up after the fact is harder, more expensive, and never fully effective.
Fuzzy Matching — When Exact Rules Aren’t Enough
Exact string matching only catches perfect variations. “Nike” won’t match “Nke” — a typo that slips through more often than you’d expect. That’s where fuzzy matching fills the gap.
If you’re managing hundreds or thousands of brand records, fuzzy matching tools can identify near-duplicates that differ by a suffix, abbreviation, or typo.
Tools like Insycle, Openprise, and DemandTools handle this well at scale. A mid-market SaaS company recorded as much as 18% duplicate companies due to naming inconsistencies. After applying normalization rules, duplicates dropped 92%, reporting accuracy for revenues increased 35%, and sales reps saved four hours a week.
Fuzzy matching should sit alongside your deterministic rules, not replace them. Run the exact rules first. Let fuzzy logic catch what slips through.
The Branding Consistency Side — Beyond CRM
Normalization isn’t just a data problem. On the customer-facing side, inconsistent brand names erode trust before a prospect even engages with your team.
Brand name normalization rules refers to the process of ensuring that your brand name is consistent across all platforms — spelling it the same, using the same logo, and keeping the tone of your messaging aligned, regardless of whether it’s online or offline.
Develop a style guide that outlines proper usage in marketing materials, social media posts, and customer communications. Regular training sessions can keep employees updated on any changes to branding rules. Continuously review your brand name usage through audits to ensure compliance with established standards.
Coca-Cola and Airbnb are the textbook examples here. Both companies built global recognition not just through advertising but through ruthless consistency in how their names appear everywhere, every time.
Building a Normalization Playbook
Ad-hoc fixes don’t scale. A documented playbook does.
Always document your rules in a shared “Normalization Playbook.” Update it quarterly as new data patterns emerge.
Update immediately when a major brand rebrands — Twitter becoming X is the obvious recent example. Brand identity changes happen, and your system needs to reflect them without creating a new wave of duplicates.
The playbook should document: canonical name decisions, exception lists for brands with non-standard styling, the order in which transformations run, and rules for edge cases like ampersands, numbers in names, and non-Latin characters.
As of 2026, AI-assisted normalization is making this process significantly faster. By 2026 and beyond, AI can do 90% of the heavy lifting with edge cases — automatically detecting mergers, inferring canonical names from context. But the playbook still matters. AI learns from your rules. Without them defined, it learns from your mess.
The Quiet Cost Nobody Talks About
Here’s the honest part most guides skip. The teams that treat normalization as a one-time cleanup project fail. The ones that bake it into every inbound lead and enrichment step win.
It’s infrastructure. Nobody gets excited about infrastructure until something breaks. And when inconsistent brand naming breaks things — a campaign targeting the same company three times under three different names, an executive dashboard that shows three different revenue figures for the same client — the cost shows up in places that are genuinely hard to trace back to a naming convention.
Get the rules right, enforce them at ingestion, and document the exceptions. That’s the entire game.

Must Read: Multipoint Control Unit (MCU): The Hidden Engine Powering Every Group Video Call
Frequently Asked Questions
What’s the difference between brand name normalization and deduplication?
Normalization standardizes the format — capitalization, suffixes, punctuation. Deduplication removes redundant records. Normalization should always run first because clean, standardized names make deduplication far more accurate.
Should I use a brand’s official stylization or apply my own standard?
Use official stylization for well-known brands like adidas or eBay. For lesser-known brands without documented style requirements, apply title case as your default. The goal is matching how customers recognize and search for the brand.
How often should brand name normalization rules be reviewed?
Quarterly reviews work for most organizations. Immediate updates are needed when a brand rebrands, merges, or gets acquired — any event that changes the canonical name in the market.
What tools actually handle this at scale?
Insycle and Openprise are the most cited for HubSpot and Salesforce environments. DemandTools works well for Salesforce-heavy teams. For smaller operations, Google Sheets with REGEX formulas can handle basic normalization without a paid tool.
Does inconsistent brand naming actually affect SEO?
Yes, directly. Inconsistent brand naming across platforms weakens your brand entity signal in search engines, reduces topical authority, and can cause your brand to appear less authoritative in knowledge panels and structured data results.
