

There’s a database running behind some of the biggest apps you use every day — handling your shopping cart, streaming your music, processing your in-game actions — and most people have never heard of it. That database is Amazon DynamoDB, and the way it manages dynamo data is unlike anything traditional SQL systems were ever designed to do.
DynamoDB handles more than 100 million requests every second and still delivers consistent, single-digit millisecond response times — trusted by companies like Amazon.com, Disney+, and Capital One. That kind of performance isn’t luck. It’s architecture.
What Dynamo Data Actually Means in the AWS World
Amazon DynamoDB is a fully managed database service that handles the heavy lifting of managing a database so developers can focus on building value for customers. It handles setup, configurations, maintenance, high availability, hardware provisioning, security, backups, monitoring, and more.
In plain terms: you create a table, and it’s production-ready immediately. No patching cycles. No server provisioning tickets. No DBA bottlenecks.
Dynamo was originally a set of techniques forming a highly available key-value structured storage system, first created to help address scalability issues Amazon experienced during the holiday season of 2004. That internal solution eventually became the public-facing DynamoDB service launched in 2012, and it’s been growing in both capability and adoption ever since.
The core data model is deceptively simple. DynamoDB is a key-value and document database that can handle massive amounts of data with high availability and low latency. It supports both key-value and document data models and automatically scales throughput capacity.
What that flexibility means in practice: you’re not locked into rigid table schemas. Your data structure can evolve as your application evolves — no migration nightmares required.
How Dynamo Data Moves So Fast
Speed is where DynamoDB genuinely separates itself from most competitors. DynamoDB guarantees single-digit millisecond latency regardless of dataset size or request volume. This is achieved through automatic data partitioning and the DynamoDB Accelerator (DAX), an integrated, in-memory cache that can boost read performance by up to 10x — taking read times from milliseconds down to microseconds.
Think about what that means for a gaming leaderboard with 10 million concurrent players. Or a flash sale hitting 500,000 transactions per minute. Traditional relational databases choke under those conditions. DynamoDB doesn’t flinch.
The architecture behind this is built on three principles: partitioning, replication, and purpose-built APIs. DynamoDB was purpose-built to improve upon the performance and scalability of relational databases. To achieve this scale and performance, DynamoDB is optimized for high-performance workloads and omits features that are inefficient at scale — for example, JOIN operations.
That last point matters more than it looks. Traditional SQL JOIN operations are expensive at scale. DynamoDB sidesteps them entirely by encouraging denormalized data models where related data lives together rather than spread across tables.
What the Research Shows: Real-World Scale Numbers
Here’s what examining DynamoDB’s production track record actually reveals:
DynamoDB APIs have handled trillions of calls from Amazon properties and systems. It continuously serves hundreds of customers with tables that have peak traffic of over half a million requests per second, and hundreds of customers whose table sizes exceed several terabytes.
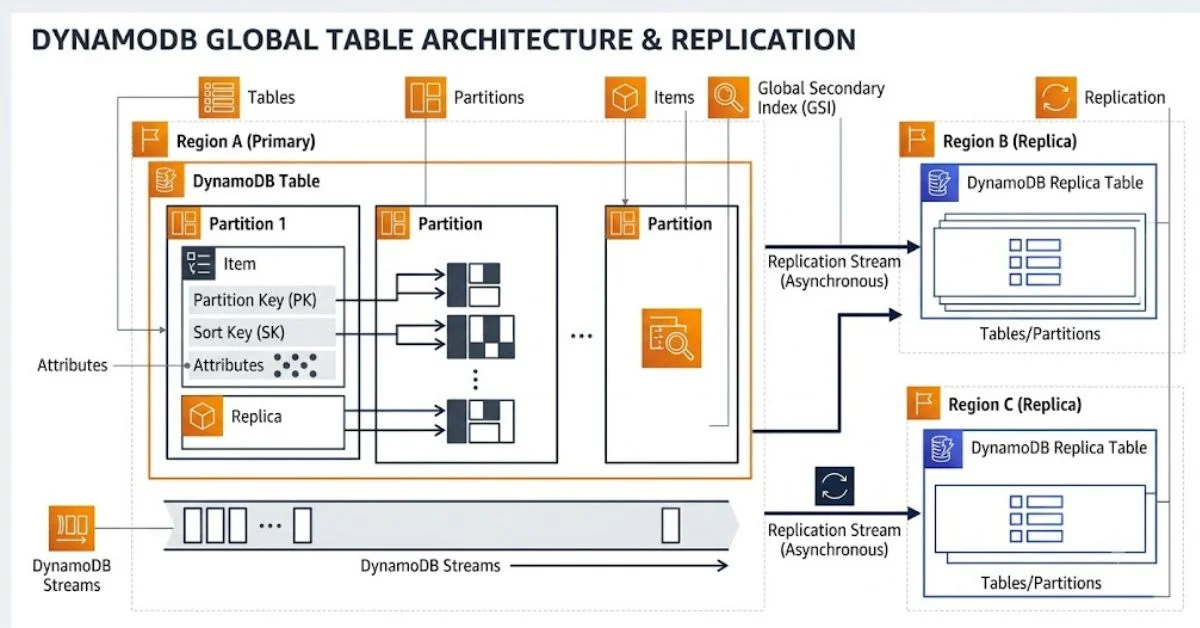
DynamoDB runs high-performance applications at any scale, with built-in security, continuous backups, and automated multi-region replication. It’s designed for 99.999% availability and the ability to always read the latest data from any region.
Those aren’t marketing numbers. They’re the kind of figures that enterprise architects put into disaster recovery planning documents. Five-nines availability means roughly five minutes of downtime per year — which is why banks, healthcare platforms, and government systems have started adopting it.
Customers choose Amazon DynamoDB for its ability to deliver consistent, single-digit millisecond performance at any scale. It’s ideal for building modern, high-performance applications, and a key part of unlocking its full potential is designing your data model around your application’s access patterns.
That last phrase is where most teams trip up early. DynamoDB rewards you for thinking about how your app reads data before you design your tables. Get that right, and the performance gains are enormous.
Dynamo Data in Practice: Who Actually Builds With This

The use cases span industries in ways that aren’t always obvious.
- E-commerce — Retail and wholesale customers choose DynamoDB for scalability, performance, resilience, and security. It helps handle high-traffic, extreme-scaled events with nearly unlimited throughput — think Black Friday surges where a conventional database would start dropping connections.
- Gaming — Leaderboards and player session data are a natural fit. Millisecond reads at any scale keep gameplay smooth even during peak hours.
- Media and Streaming — DynamoDB scales throughput and concurrency for media and entertainment workloads like real-time video streaming and interactive content, and delivers lower latency with multi-region replication across AWS regions.
- IoT — IoT applications can leverage DynamoDB’s scalability and durability to efficiently store and process data from millions of connected devices.
And then there’s the financial services angle. DynamoDB has a broad set of security controls and compliance standards built to satisfy the requirements of governments, global banks, and other high-sensitivity organizations.
DynamoDB Pricing Models at a Glance
| Mode | Best For | Cost Behaviour |
|---|---|---|
| On-Demand | Unpredictable traffic | Pay per request |
| Provisioned | Steady workloads | Fixed hourly rate |
| Reserved | Long-term predictable | Up to 76% savings |
Dynamo Data Integration: How It Plugs Into the AWS Ecosystem
One thing that makes dynamo data management genuinely powerful is how DynamoDB connects to the broader AWS stack. AWS Lambda can trigger functions in response to DynamoDB Streams. Kinesis Data Streams can stream changes for analytics or machine learning. Amazon CloudWatch monitors table metrics and performance. AWS Glue handles ETL jobs and analytics pipelines. These integrations help build event-driven and analytics-ready architectures easily.
The Streams feature deserves special mention. Every change to a DynamoDB table — inserts, updates, deletes — can trigger downstream processes automatically. A new user record gets created, and within milliseconds a welcome email fires, a recommendation engine updates, and an audit log writes. All without a single polling loop in your application code.
A new DynamoDB data modeling tool, available as part of the DynamoDB Model Context Protocol (MCP) server, was introduced in mid-2025 to help development teams move faster with greater confidence when designing data models. After requirements are confirmed, a data model is generated and output directly to a markdown file.
That’s the direction AWS is pushing: less manual schema work, more AI-assisted data architecture. As of 2026, this tooling is actively being adopted by teams building complex serverless applications.
Where Dynamo Data Has Limits
No database is right for everything, and DynamoDB’s constraints are worth knowing upfront.
A transaction cannot update more than 100 unique items. A transaction cannot contain more than 4 MB of data. DynamoDB has a size limit of 400 KB for each item. Transactional operations provide ACID guarantees only within the AWS region where the write operation originally takes place — transactions are not supported across regions in global tables.
For heavy analytics workloads requiring complex ad-hoc queries across large datasets, DynamoDB isn’t the right primary tool. It’s optimized for operational workloads — predictable access patterns at high velocity — not analytical workloads with unpredictable query shapes. AWS recommends pairing it with Athena or Redshift for the analytics layer.
Cost structure is also something teams need to model carefully before committing. On-demand pricing is flexible for unpredictable traffic. Provisioned capacity with reserved pricing rewards predictable workloads. Getting that choice wrong can mean unexpectedly high bills during traffic spikes.
| Use Case | DynamoDB Fit | Better Alternative |
|---|---|---|
| E-commerce cart | ✅ Excellent | — |
| Gaming leaderboards | ✅ Excellent | — |
| Real-time IoT | ✅ Excellent | — |
| Complex analytics | ❌ Weak | Redshift / Athena |
| Heavy JOIN queries | ❌ Weak | PostgreSQL / MySQL |
| Ad-hoc reporting | ❌ Weak | BigQuery |
The Bigger Picture: Why Dynamo Data Matters in 2026
The shift happening across the industry right now is about developers owning their infrastructure less and their application logic more. Serverless databases like DynamoDB sit at the center of that shift.
DynamoDB continuously improves its availability, reliability, performance, security, and functionality without requiring upgrades or downtime. That’s a meaningful promise — your database gets better over time without you scheduling maintenance windows or managing version migrations.
Industry analysts note that the NoSQL database market continues to grow faster than relational alternatives, driven by the explosion of real-time applications, mobile backends, and event-driven architectures. DynamoDB sits at the center of that growth on the AWS side, with adoption across startups building their first app and enterprises running operations at global scale.
Anyone who has tried to scale a traditional relational database under sudden, unpredictable traffic spikes knows what the alternative feels like. DynamoDB was designed precisely for that moment — so the answer to “can our database handle this?” is always yes.
Also Read: Business Intelligence Exercises That Actually Build Real Skills
FAQ
1. What is dynamo data in the context of AWS?
Dynamo data refers to data stored and managed within Amazon DynamoDB — AWS’s fully managed NoSQL database service built for high-speed, high-scale applications. It uses a key-value and document data model rather than traditional relational tables.
2. How fast is DynamoDB really?
DynamoDB consistently delivers single-digit millisecond response times at any scale. With DAX (DynamoDB Accelerator), read speeds can drop to microseconds — making it one of the fastest managed database options available in cloud computing.
3. Is DynamoDB suitable for small applications?
Yes. DynamoDB’s on-demand pricing means you only pay for what you use, so small applications don’t pay for unused capacity. It’s equally suited to a startup’s MVP and a Fortune 500 company’s core infrastructure.
4. What’s the biggest limitation of DynamoDB?
The main constraint is its item size limit of 400 KB and the requirement to design data models around known access patterns. It’s not ideal for complex ad-hoc queries or heavy analytics — for those, pairing it with AWS Athena or Redshift works better.
5. How does DynamoDB handle global applications?
Through Global Tables, DynamoDB replicates data across multiple AWS regions automatically. This enables active-active multi-region setups with 99.999% availability, letting users in any geography read from and write to their nearest region with minimal latency.
